
A decoder-only foundation model for time-series forecasting-论文阅读
Date:
工作简要
该工作提出了一种time series foundation model,名为TimesFM。该工作的关键在于构建了一个时间序列预测数据集,该数据集由Google trends, Wiki Pageviews和合成数据组成。TimesFM的性能上略微优胜llmtime,也优胜了traditional methods。
摘要
我们见证了LLM在NLP中的快速发展。这随之产生一个问题,LLM是否也可以应用在时间序列当中,出现zero-shot等能力?作者认为,LLM应用在时间序列的困难在于
1)时间序列不存在一个已经定义好的字典和语法。
2) 要支持可变长的输入和输出。
3)足够的数据。
因此,作者提出了TimeFM,主要贡献有2点:
1)用google trend和Wikipedia page visit和合成数据构建了数据集。
2)一种decoder的架构。
亮点:
TimeFM使用了100B的time points训练,参数只有200M。但能达到与full supervised methods相媲美的结果。
模型架构
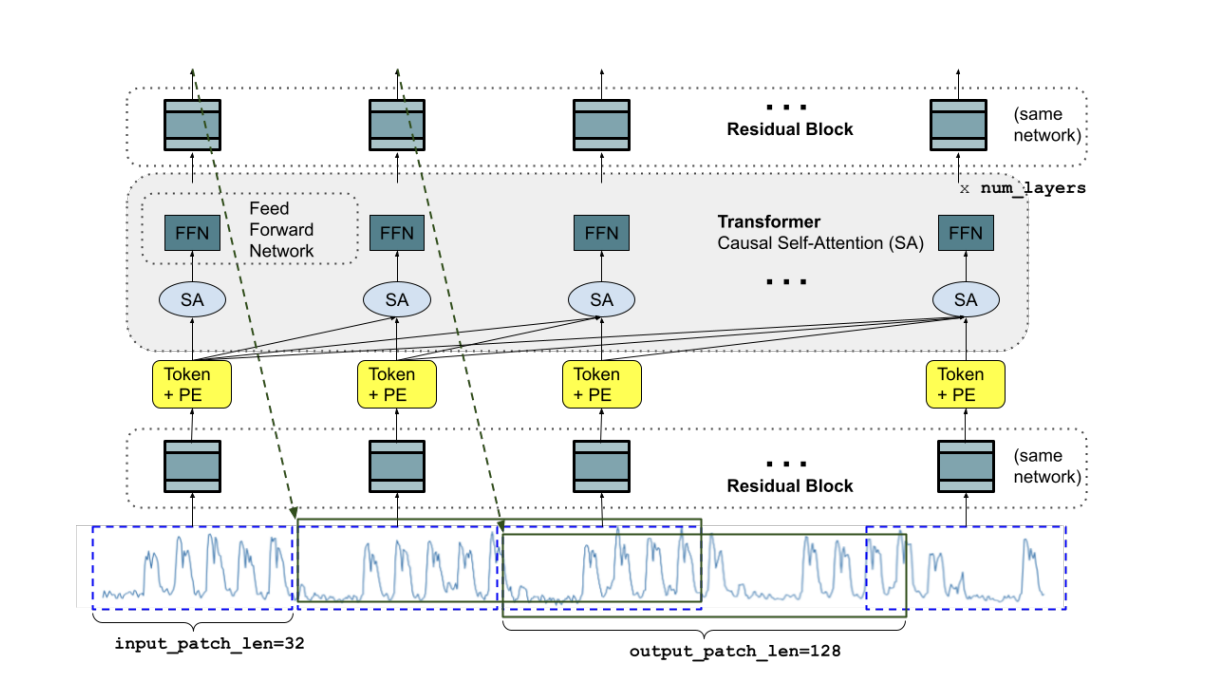
TimesFM支持可变的上下文长度。
Longer output patches:输出总是以自动回归的方式生成,每次生成一个token。然而,在long horizon预测中,直接预测full horizon比multi step自回归解码产生更好的准确性。但是,当horizon长度不是先验已知时,很难实现full horizon,尤其在我们的zero-shot的环境下。
因此作者提出了一种中间想法,允许输出比输入patches长(output patch length更长一些,也是AR)。例如,假设输入的patch长度为32,输出的patch长度为128。在训练过程中,使用前32个时间点预测接下来的128个时间步长,使用前64个时间点预测时间步长65~192,使用前96个时间点预测时间步长97~224,以此类推。在推理阶段,假如给定长为256的时间序列,预测接下来的256个时间步长。模型首先用前256预测接下来的128个时间步,再利用原始256个时间序列+128个预测时间步预测385~512的时间序列。
结构上没有特别的创新,传统的decoder+casual attention结构,唯一有一些区别的是mask方式。
Training:
假设 =4为随机掩码数,patch 长度 为32,那么TimesFM将看到第一个patch后的输出预测优化为看到28 = 32−4个时间点后预测,将看到第二个patch的输出优化为看到28 + 32个时间点后预测,以此类推。(这部分有些疑惑,为什么不是每个pach进行随机掩码,只对第一个patch随机掩码?)
Inference:
将输入序列padding至patch 长度的整数倍,进行AR预测。padding的部分对应mask置为1。
数据集
主要从三个来源获取用于训练模型的大量数据: google trends、Wiki Pageview statistics、synthetic time series。
Google trends: Google Trends捕捉了数百万查询的搜索兴趣。从2007年到2022年的15年间,作者根的搜索兴趣选择了大约22k个head query。作者下载了每小时、每天、每周和每月这些query的搜索兴趣,形成了其中的一个数据集。该数据集有1B个time points。
Wiki Pageview statistics: 捕获所有维基媒体页面的每小时浏览量。作者下载了2012年1月至2023年11月的所有页面浏览量数据,将页面浏览量按小时、日、周、月的粒度进行清理和汇总,并过滤掉过多零的页面浏览量时间序列。最终的语料库包含大约100B个time points。
Synthetic time series: 预训练数据的另一个主要组成部分是合成来源。作者为ARMA 过程、季节模式(不同频率的正弦和余弦的混合)、趋势(线性、指数和几个变化点)和阶跃函数创建了generator。合成时间序列可以是这些过程中的一个或多个的加性组合。作者创建了3M个的合成时间序列,每个序列长度为2048个time points。
Other real-world data sources: M4数据集,Informer dataset。
数据集训练策略:作者对上述数据集进行混合训练,目的是为所有粒度赋予足够的权重。训练加载器对40%的真实数据和60%的合成数据进行采样,真实数据混合为所有小时+次小时、每日、每周和每月数据集提供相同的权重。只要时间序列的长度允许,训练的最大上下文长度为512。对于周粒度,我们没有足够长的时间序列;因此,使用的最大上下文长度为256。出于同样的原因,当训练≥月粒度的数据时,最大上下文长度为64。
Performance
作者在Darts,Informer数据集(etth1,etth2,ettm1,ettm2),Monash archive(只有18个数据集,过滤了missing values的数据集)上测试了TimesFM的zero-shot能力。
在实验这部分个人感觉没有很亮眼的部分,总的结论就是TimesFM的zero-shot能力能和监督学习的方法媲美。虽然在monash archive的平均MAE不如N-beats和Catboost方法,但作者表明,TimesFM的关键在于zero-shot能力。后两者的方法都是在对应的数据集上训练得到的模型。
论文延伸:
大规模语言模型(Large Language Models,LLMs)的构造通常基于深度学习架构,尤其是自注意力机制(self-attention)的变体,如变压器(Transformer)。以下是 LLMs 构建的一般概述:
1. 模型架构
变压器(Transformer)架构
LLMs 通常使用变压器架构,它由编码器(encoder)和解码器(decoder)组成。典型的 LLMs,如 GPT(生成式预训练变换器),主要使用解码器部分,而 BERT(双向编码器表示的变换器)使用编码器部分。
自注意力机制:这是变压器的核心组件,允许模型在处理每个词时考虑输入序列中所有其他词。自注意力机制能够捕捉上下文和长距离依赖关系,克服了传统 RNN 和 LSTM 的局限性。
多头注意力:这一机制允许模型在不同的子空间中学习不同的表示,增强了模型的表示能力。
前馈神经网络:在每个注意力层后,数据通过一个前馈神经网络进行进一步处理。这些网络通常是全连接的,并包括激活函数(如ReLU)。
位置编码(Positional Encoding):因为变压器架构不包含序列顺序的信息,位置编码被添加到输入嵌入中,以帮助模型理解词之间的相对位置。
2. 模型训练
预训练与微调
预训练(Pre-training):LLMs 首先在大量文本数据上进行无监督的预训练。这个阶段,模型通常学习语言的基本结构和词语之间的关系。常见的方法包括语言建模任务(预测下一个词)和遮掩语言模型任务(预测被遮掩的词)。
微调(Fine-tuning):预训练之后,模型在特定任务的数据集上进行有监督的微调,以优化其在特定应用场景中的性能。例如,对于情感分析任务,模型会在标注了情感类别的文本数据上进行微调。
3. 大规模与分布式训练
由于 LLMs 通常包含数十亿甚至上千亿个参数,训练这些模型需要大量的计算资源和时间。因此,分布式计算和并行处理技术被广泛应用。常见的策略包括:
- 模型并行:将模型的不同部分分配到不同的计算设备上。
- 数据并行:将训练数据划分为多个批次,每个批次在不同的设备上并行处理。
- 混合精度训练:使用低精度(如半精度浮点数)来加速训练并减少内存占用,同时保持模型的精度。
4. 模型应用
LLMs 可以应用于广泛的自然语言处理任务,如文本生成、翻译、问答、摘要、对话系统等。它们的广泛适应性和强大的语言理解能力使其在许多领域中都有着广泛的应用。